20. A/B Testing Tools¶
from datascience import *
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
from scipy import stats
I keep some data frames in CSV format accessible from my website. One of them is called personality.csv and has, as you might imagine, personality variables. In this case, we are using a subset of the personality data with variables like perfectionsism, narcissism with grouping variables like biological sex and the AccDate variable which has Yes/No responses to the following question:
“At a time in your life when you are not involved with anyone, a person asks you out. This person has a great personality, but you do not find this person physically attractive. Do you accept the date?”
The Stress1 and Stress2 variables are pre-post data collected from the 2nd week and 7th week of the semester respectively to see if college students experience more stress during midterms.
pers = Table.read_table('http://faculty.ung.edu/rsinn/perfnarc.csv')
pers
| Sex | G21 | Greek | AccDate | Stress1 | Stress2 | Perf | Narc |
|---|---|---|---|---|---|---|---|
| F | N | N | N | 9 | 7 | 99 | 3 |
| F | Y | N | Y | 11 | 13 | 86 | 2 |
| F | N | Y | N | 15 | 14 | 118 | 4 |
| F | N | N | Y | 16 | 15 | 113 | 2 |
| F | Y | N | Y | 17 | 17 | 107 | 8 |
| F | N | N | N | 10 | 7 | 123 | 1 |
| F | N | N | N | 16 | 18 | 93 | 4 |
| F | N | Y | Y | 12 | 12 | 126 | 7 |
| F | N | N | Y | 11 | 16 | 91 | 5 |
| F | Y | N | Y | 18 | 16 | 111 | 1 |
... (138 rows omitted)
Tools for A/B Testing¶
As we walk through an example with narcissism, we will build three functions that will help us conduct A/B tests.
ab_shuffleab_diffab_hist
All three expect an input of a 2-column table with the grouping variable in the first column and a numeric variable in the second.
Creating a 2-column table for A/B Testing¶
We will use the grouping variable of biological sex and numeric variable of narcissism scores.
narc = pers.select('Sex','Narc')
narc.group('Sex')
| Sex | count |
|---|---|
| F | 85 |
| M | 63 |
narc.group('Sex', np.average)
| Sex | Narc average |
|---|---|
| F | 3.81176 |
| M | 5.57143 |
Calculating observed difference in means for A/B groups¶
a_mean = narc.group(0,np.average).column(1).item(0)
a_mean
3.8117647058823527
b_mean = narc.group(0,np.average).column(1).item(1)
b_mean
5.571428571428571
observed_difference = a_mean - b_mean
observed_difference
-1.7596638655462185
integer_bins = np.arange(15)
narc.hist('Narc', group = "Sex", bins = integer_bins)
_= plots.title('Narcissism by Sex')
C:\Users\robbs\anaconda3\envs\datasci\lib\site-packages\datascience\tables.py:920: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
values = np.array(tuple(values))
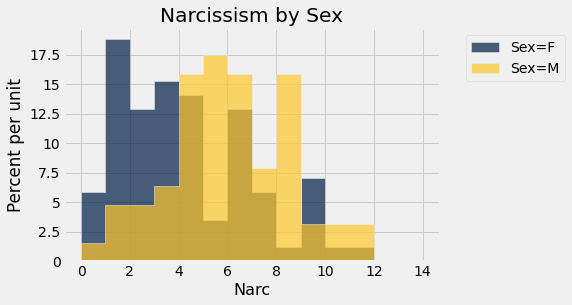
The A/B hypothesis test for differences in narcissism based on biological sex¶
The null hypothesis is that the male and female groups are drawn from the same distribution. If so, then randomly shuffling the grouping labels should not matter. The observed difference in A/B means should fall well within the distribution of shuffled differences in A/B means which we can simulate.
Creating ab_shuffle: a function for shuffling the grouping labels¶
Let’s first demonstrate step by step what we need the function to do. Then we can create the function. The first code block below demonstrates our “shuffle” command which uses the sample method and draws without replacement.
shuffle_sex = narc.sample(with_replacement = False)
shuffle_sex.show(5)
| Sex | Narc |
|---|---|
| F | 3 |
| F | 2 |
| F | 0 |
| M | 5 |
| F | 4 |
... (143 rows omitted)
shuffle_sex = narc.sample(with_replacement = False).column(0)
shuffle_sex
array(['M', 'F', 'F', 'M', 'F', 'M', 'F', 'M', 'M', 'F', 'F', 'F', 'F',
'F', 'F', 'F', 'M', 'M', 'F', 'F', 'M', 'F', 'F', 'F', 'M', 'F',
'F', 'F', 'F', 'F', 'F', 'M', 'M', 'M', 'F', 'F', 'M', 'F', 'F',
'M', 'M', 'M', 'M', 'M', 'F', 'F', 'F', 'F', 'F', 'M', 'M', 'F',
'F', 'M', 'F', 'M', 'M', 'F', 'F', 'F', 'F', 'F', 'F', 'F', 'M',
'M', 'M', 'M', 'F', 'F', 'M', 'M', 'M', 'M', 'F', 'F', 'M', 'M',
'F', 'F', 'F', 'M', 'F', 'F', 'F', 'F', 'M', 'F', 'F', 'F', 'F',
'F', 'M', 'M', 'M', 'F', 'M', 'F', 'F', 'M', 'M', 'F', 'M', 'M',
'M', 'M', 'M', 'F', 'F', 'F', 'M', 'M', 'F', 'M', 'M', 'M', 'M',
'F', 'F', 'M', 'F', 'F', 'F', 'M', 'F', 'F', 'F', 'F', 'F', 'F',
'M', 'M', 'M', 'F', 'F', 'F', 'F', 'M', 'F', 'F', 'M', 'F', 'F',
'F', 'M', 'M', 'M', 'M'], dtype='<U1')
After creating an array of shuffled labels, we need to include that array as column in our table. We can add the shuffled labels as a third column, then use the select method to create a two-column table with the columns in the correct order.
shuffled_narc = narc.with_column("Shuffled Grouping",shuffle_sex)
shuffled_narc.show(5)
| Sex | Narc | Shuffled Grouping |
|---|---|---|
| F | 3 | M |
| F | 2 | F |
| F | 4 | F |
| F | 2 | M |
| F | 8 | F |
... (143 rows omitted)
shuffled_narc = narc.with_column("Shuffled Grouping",shuffle_sex).select(2,1)
shuffled_narc.show(5)
| Shuffled Grouping | Narc |
|---|---|
| M | 3 |
| F | 2 |
| F | 4 |
| M | 2 |
| F | 8 |
... (143 rows omitted)
shuffled_narc.group('Shuffled Grouping',np.average)
| Shuffled Grouping | Narc average |
|---|---|
| F | 4.6 |
| M | 4.50794 |
The ab_shuffle function¶
Our function just combines the previous several code blocks. Notice that the expected input is a two-column table with the grouping variable be in the first column.
def ab_shuffle(tab):
shuffle_group = tab.sample(with_replacement = False).column(0)
shuffled_tab = tab.with_column("Shuffled Grouping",shuffle_group).select(2,1)
return shuffled_tab
ab_shuffle(narc)
| Shuffled Grouping | Narc |
|---|---|
| M | 3 |
| M | 2 |
| M | 4 |
| M | 2 |
| F | 8 |
| M | 1 |
| F | 4 |
| F | 7 |
| M | 5 |
| F | 1 |
... (138 rows omitted)
Creating ab_diff: a function that calculates the difference in A/B group means¶
We can add a function to the .group method to find the A/B group means.
shuffled_narc.group('Shuffled Grouping',np.average)
| Shuffled Grouping | Narc average |
|---|---|
| F | 4.6 |
| M | 4.50794 |
a_mean = shuffled_narc.group('Shuffled Grouping',np.average).column(1).item(0)
a_mean
4.6
b_mean = shuffled_narc.group('Shuffled Grouping',np.average).column(1).item(1)
b_mean
4.507936507936508
diff = a_mean - b_mean
diff
0.09206349206349174
The ab_diff function¶
Using the above code blocks as a template, we can write a function that grabs the means from the grouping table. Again, the expected input is a two-column table with the grouping variable first.
def ab_diff(tab):
tab.group(0,np.average)
a_mean = tab.group(0,np.average).column(1).item(0)
b_mean = tab.group(0,np.average).column(1).item(1)
return a_mean - b_mean
ab_diff(shuffled_narc)
0.09206349206349174
Simulating the statistic¶
The statistic we need is the difference in shuffled A/B group means. Our plan is to use a for loop to repeatedly reshuffle the labels and calculate this statistic. The output will be an array representing a random sampling of this statistic.
The engine in the for loop is quite simple. We shuffle the data table and calculate the difference in A/B means in one line using the two functions we created above.
diffs = make_array()
# Reduce reps to 1,000 or less, especially if running in cloud.
reps = 5000
for i in range(reps):
new_diff = ab_diff(ab_shuffle(narc))
diffs = np.append(diffs, new_diff)
# Remove the hashtag/comment symbol to see the array output
# diffs
Displaying the distribution of the null hypothesis statistic¶
Let’s create a third function, one that will take an array of simulated statistics along with an observed value and plot a histogram showing both.
def ab_hist(myArray, observed_value):
tab = Table().with_column('A/B Differences',myArray)
tab.hist(0)
_ = plots.plot([observed_value, observed_value], [0, 0.1], color='red', lw=2)
ab_hist(diffs,observed_difference)
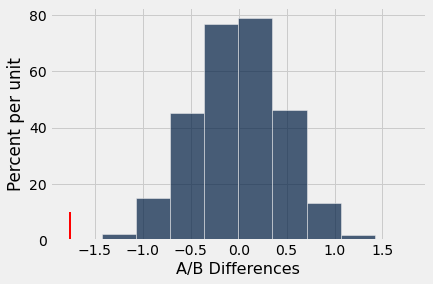
Conside what the above visualization means.
The blue histogram represents the null hypothesis statistic
The red line indicates the observed value of the statistic
To calculate a \(p\)-value, we first creat a truth array for the number of randomized A/B differences in means that were less than the observed_difference. Then we can sum the truth array which counts all simulated values at least as extreme as the observed value.
sum(diffs <= observed_difference)
1
p_val = sum(diffs <= observed_difference) / reps
p_val
0.0002
Results of Example A/B Test¶
Because p_val is far less than \(0.05\), we reject the null. In real world terms, we conclude that there is strong evidence that a significant difference exists in Narcissism levels based upon biological sex.