Exploratory Data Analysis#
The 2 key questions as we conduct an exploratory data analysis are as follows:
What is the shape of the distribution?
Do outliers or skew exist?
The most significant shape of distributions for introductory statistics is the normal distribution since parametric statistical tests like the
\(z\)-test,
\(t\)-test, and
ANOVA
are built on assumptions of normality. We also need to know whether or not skew and outliers exist because we often must treat skewed data and outliers with care and possibly different tools.
Types of Data#
Data come in two varieties: quantitative (numeric) or qualitative (categorical) data. Poker player Pete plays Heads Up tournaments with a 20 dollar buy-in (HU20). These two-player tournaments take less than half an hour where he either loses 21, or wins 19. (The online casino takes a cut of each tournament buy-in, called the rake.) Pete’s HU20 win-loss record is category data, a series of W’s and L’s.
Pete’s friend Mandy, a math major with a data science minor at North Georgia, enjoys 6-max NL10, a small stakes cash game. Mandy’s list of winnings from her past twenty cash game sessions is numeric data.
For numeric data sets, we have a sample of \(n\) data points:
Parameters and Statistics#
We will continue to emphasize the difference between parameters and statistics:
Parameters#
The population parameters of mean \(\mu\) and standard deviation \(\sigma\) are typically the values of greatest interest. Also typically, they are rarely known. Consider a study at UNG Dahlonega where we wish to know the Perfectionism levels for undergraduate students. We know little about the overall population parameters but can collect sample data from, say, 200 students to launch our investigation.
Statistics#
The sample statistics of mean \(\bar x\) and standard deviation \(s\) are known and thus can be used to estimate the population parameters. The accuracy of the estimates will depend upon two things, among others:
Shape of the data
Sample size
The shape of the distribution the data are drawn from matters due to the fact that we handle different distributions in different ways. Larger samples lead to improved accuracy.
Example 1
Recall our data from Example 1 which were winnings and losses from Mandy’s 20 most recent poker sessions.
| 28 | 11 | 18 | 35 | 36 | 6 | -38 | 14 | -19 | 43 |
| -14 | -30 | -16 | -25 | 0 | 40 | 16 | -79 | 3 | 1 |
Tip
In R, the concatenate function c() is widely useful. Here, we use it to create a data vector where we can type in the values from a list.
W <- c( 28, 11, 18, 35, 36, 6, -38, 14, -19, 43, -14, -30, -16, -25, 0, 40, 16, -79, 3, 11)
Using our code and the cat() function from an earlier section, we have the following:
cat('The standard descriptives for Winnings \n Mean = ', round(mean(W),2),
'\n Standard Deviation = ', round(sd(W),2),
'\n Sample Size = ', length(W),
'\n\nThe 5-number summary for Winnings')
summary(W)
The standard descriptives for Winnings
Mean = 2
Standard Deviation = 30.57
Sample Size = 20
The 5-number summary for Winnings
Min. 1st Qu. Median Mean 3rd Qu. Max.
-79.00 -16.75 8.50 2.00 20.50 43.00
Analysis of Descriptives#
The most interesting feature of the descriptive statistics is that the mean and median are quite different. Since the median is \(8.5\) and the mean is \(2\), their difference is \(6.5\) which is about \(\frac{1}{4}\) of standard deviation.
In this example, because the mean is significantly less than the median, we anticipate skew to the left and outliers, if present, to be on the left, which brings up the second detail one should notice. There is a much longer tail to the left shown the Five Number Summary. The Lower Quartile spans the interval \((−79,−17.5)\) or more than \(60\) units. The upper Quartile spans only \((23,43)\) or \(20\) units. This indicates likely skew to left since the lower Quartile range is much larger and hence has more room for outliers.
Example 2#
Recall that standardardized scores are calculated as \(z = \frac{x-\mu}{\sigma}\). SAT math section scores have the \(N(500,100)\) distribution meaning the population average is 500 and the standard deviation is 100. If Brea earns a 630 on her math SAT section, what is her standardized score?
The interpretation? Brea’s raw score is 1.3 standard deviation above average. A negative \(z\) score indicates a score that is below average.
Outliers#
We have two different ways of checking for outliers:
Based upon mean and standard deviation.
Based upon the 5-Number Summary: Q1, Q3, and IQR.
Outliers Based upon Meand and Standard Deviation#
The basic rule is that any data point more than 2 standard deviations from the mean will count as an outlier in a small data set where small indicates a sample of \(n\leq 200\). For larger sample sizes, a 3 standard deviations from the mean may be more appropriate. We will create cutoff points above and below mean as follows:
Upper Cutoff: \(\bar x + 2s\)
Lower Cutoff: \(\bar x - 2s\)
Any data point above the Upper Cutoff will be counted as an outlier. Any data point below the Lower Cutoff will be counted as an outlier.
Outliers Based upon 5-Number Summary#
The box plot checks for outliers using fences which are calculated as follows:
Upper Fence: Q3 + 1.5 * IQR
Lower Fence: Q1 - 1.5 * IQR
where the inner quartile range (IQR) is given by:
Again, any data points that lie outside or beyond the fences are designated as outliers. The only difference between the two methods is the formula used to calculate the cutoff points.
Analysis of Shape#
Describing the Distribution of a Quantitative Variable#
Shape: Symmetry or Skew
Shape: Uniform, Peaks - unimodal, bimodal, others
Center: Mean and Median
Spread: Range, IQR, standard deviation
Outliers
Run the cell below to see examples of different shape characteristics.
set.seed(844)
setA <- rnorm(500,21,2)
setB <- rchisq(500,df=800)
setC <- rchisq(500,df=6)
setD <- -1*setC+30
setE <- runif(5000,min=1,max=6)
setF <- c(rnorm(500,21,2),rnorm(500,32,2))
par(mfrow=c(3,2))
hist(setA,main="Approximately Normal", xlab="Data Set A")
hist(setB,main="Unimodal and Roughly Symmetric", xlab="Data Set B")
hist(setC,main="Unimodal and Skewed RIGHT", xlab="Data Set C")
hist(setD,main="Unimodal and Skewed LEFT", xlab="Data Set D")
hist(setE,main="Approximately Uniform", xlab="Data Set E")
hist(setF,main="Bimodal", xlab="Data Set F")
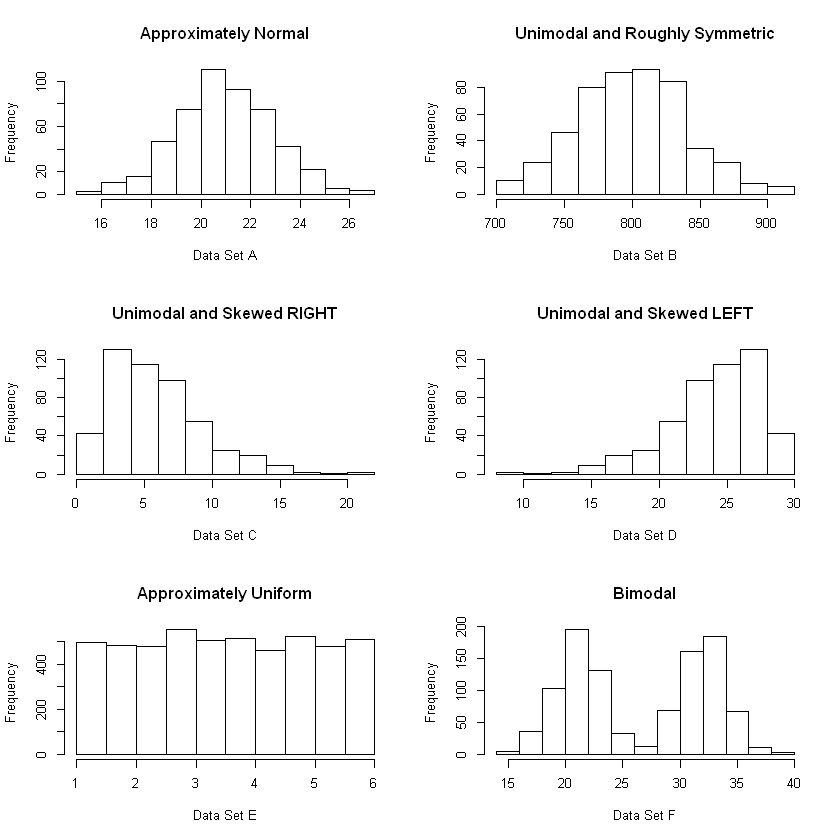
Skew and Outliers#
If a distribution has skew, then the majority of outliers in that data set are likely to lie in the same direction. Why do we care?
Outliers are called influential data points because they affect the mean.
The median is not affected much by outliers.
Thus, in the presence of skew, we can see where the majority of these influential data points are likely to live.
Example
Due to the influential data points, e.g. outliers, the following are true:
If the distribution is skewed left, the mean is likely to be less than the median.
If the distribution is skewed right, the mean is likely to be greater than the median.
Example 3#
Perform exploratory data analysis for Life Expectancy in 2015 using the World Health Organization country-by-country comparison data.
life <- read.csv('https://faculty.ung.edu/rsinn/data/lifeexpectancy.csv')
life <- subset(life, Year == 2015)
head(life,7)
| Country | Year | Status | LifeExpectancy | AdultMortality | InfantDeaths | Alcohol | PercentageExpenditure | HepatitisB | Measles | ... | Polio | TotalExpenditure | Diphtheria | HIV.AIDS | GDP | Population | Thinness_.1.19_years | Thinness_5.9_years | Income | SchoolingYrs | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Afghanistan | 2015 | Developing | 65.0 | 263 | 62 | 0.01 | 71.27962 | 65 | 1154 | ... | 6 | 8.16 | 65 | 0.1 | 584.2592 | 33736494 | 17.2 | 17.3 | 0.479 | 10.1 |
| 17 | Albania | 2015 | Developing | 77.8 | 74 | 0 | 4.60 | 364.97523 | 99 | 0 | ... | 99 | 6.00 | 99 | 0.1 | 3954.2278 | 28873 | 1.2 | 1.3 | 0.762 | 14.2 |
| 33 | Algeria | 2015 | Developing | 75.6 | 19 | 21 | NA | 0.00000 | 95 | 63 | ... | 95 | NA | 95 | 0.1 | 4132.7629 | 39871528 | 6.0 | 5.8 | 0.743 | 14.4 |
| 49 | Angola | 2015 | Developing | 52.4 | 335 | 66 | NA | 0.00000 | 64 | 118 | ... | 7 | NA | 64 | 1.9 | 3695.7937 | 2785935 | 8.3 | 8.2 | 0.531 | 11.4 |
| 65 | Antigua and Barbuda | 2015 | Developing | 76.4 | 13 | 0 | NA | 0.00000 | 99 | 0 | ... | 86 | NA | 99 | 0.2 | 13566.9541 | NA | 3.3 | 3.3 | 0.784 | 13.9 |
| 81 | Argentina | 2015 | Developing | 76.3 | 116 | 8 | NA | 0.00000 | 94 | 0 | ... | 93 | NA | 94 | 0.1 | 13467.1236 | 43417765 | 1.0 | 0.9 | 0.826 | 17.3 |
| 97 | Armenia | 2015 | Developing | 74.8 | 118 | 1 | NA | 0.00000 | 94 | 33 | ... | 96 | NA | 94 | 0.1 | 369.6548 | 291695 | 2.1 | 2.2 | 0.741 | 12.7 |
le <- life[ , 'LifeExpectancy']
head(le,4)
- 65
- 77.8
- 75.6
- 52.4
Example 3: Shape#
Let’s consider shape by constructing a histogram and a density plot.
hist(le, breaks = 10, main = 'Histogram: Life Expectancy in 2010',xlab = "Years")
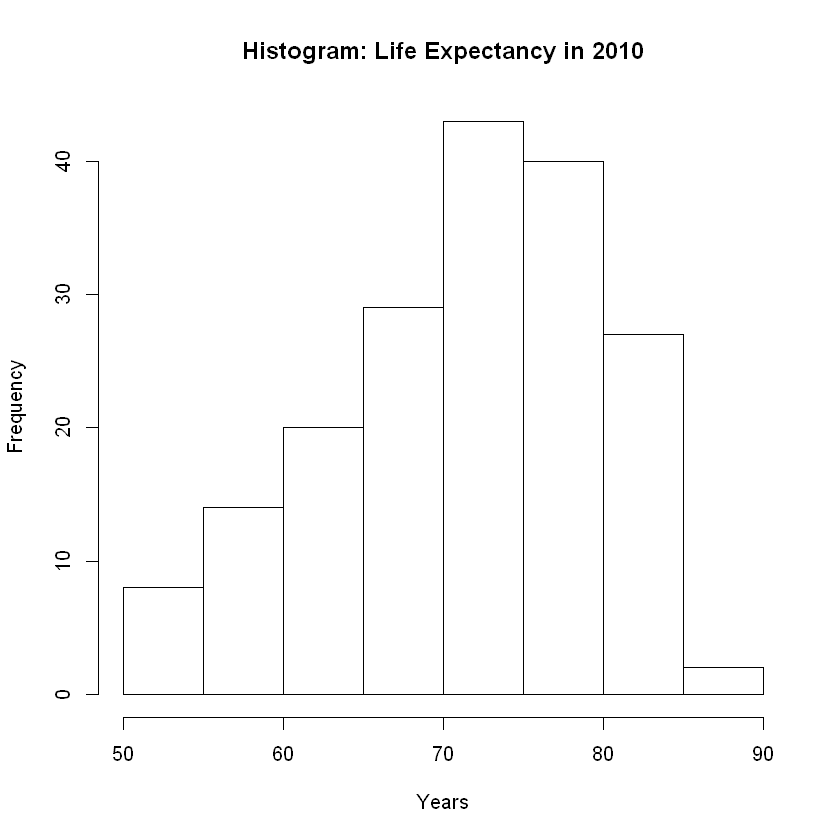
plot(density(le), main = 'Histogram: Life Expectancy in 2010',xlab = "Years")
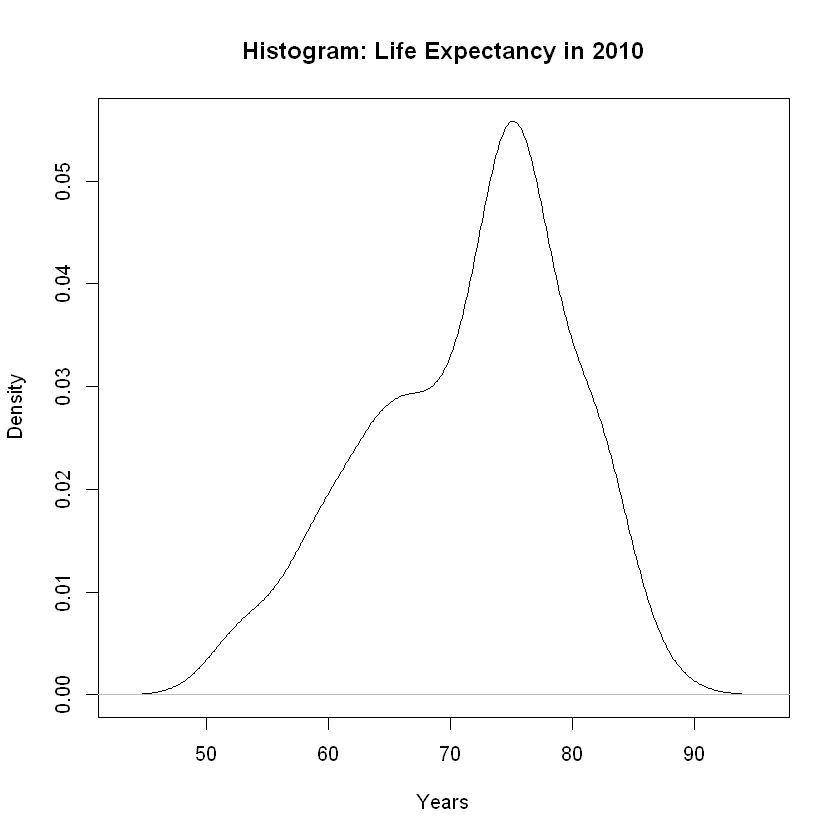
We have a normal or bell-shaped distribution. Given the longer tail to the left, we are seeing some skew to the left and anticipate outliers in that direction.
Example 3: Outliers#
Let’s create a boxplot to investigate skew and outliers.
boxplot(le, main = 'Life Expectancy', ylab = 'Years')
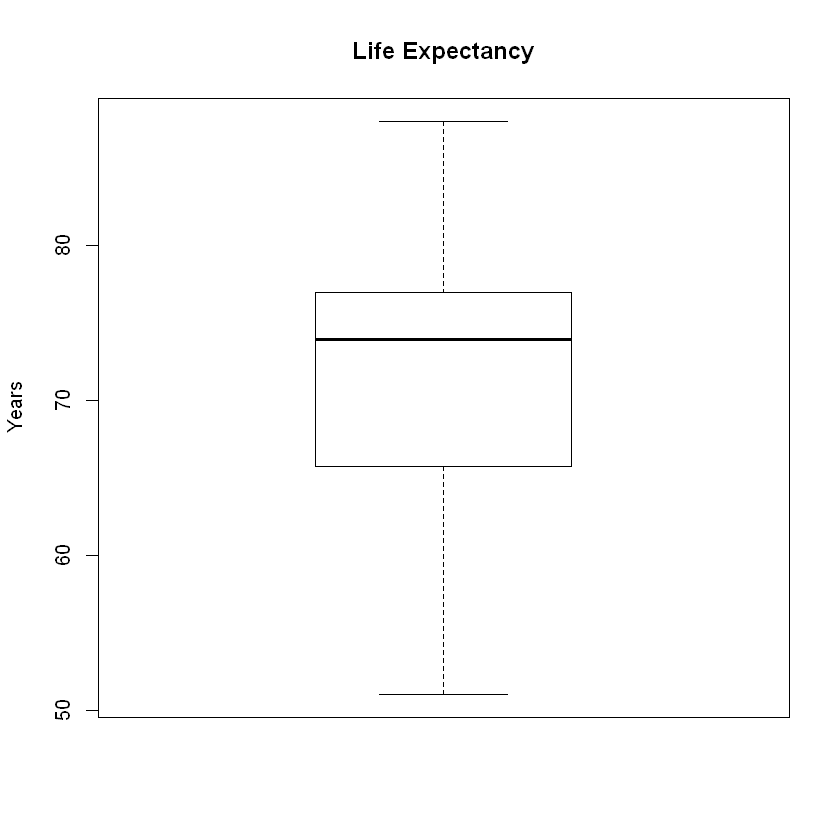
We see no outliers in the boxplot, but we do see a slightly longer tail to the left. Checking numerically, we find that:
upper_cutoff = mean(le) + 2 * sd(le)
lower_cutoff = mean(le) - 2 * sd(le)
upper_cutoff
lower_cutoff
sum(le < lower_cutoff)
sum(le > upper_cutoff)
Using the boxplot method for checking for outliers, we find:
Upper Fence = Q3 + 1.5 * IQR
Lower Fence = Q1 - 1.5 * IQR
summary(le)
Min. 1st Qu. Median Mean 3rd Qu. Max.
51.00 65.75 73.90 71.62 76.95 88.00
IQR = 76.95 - 65.75
upper_fence = 76.95 + 1.5 * IQR
lower_fence = 65.75 - 1.5 * IQR
upper_fence
lower_fence
sum(le < lower_fence)
sum(le > upper_fence)
Notice that two methods differ. While the box plot shows no outliers, the numeric method identifies 8 outliers to the left with only 1 to the right. The methods do differ at times, especially when the outliers in discrepency are marginal. If a data point is 4 standard deviations from the mean, both methods will identify it as an outlier. When close the cutoff points, some data points will be classified differently by the two methods.
Given several marginal outliers to the left and 1 to the right, we see the skew to the left.
Example 3: Descriptive Statistics#
cat('The standard descriptives for Life Expectancy \n Mean = ', round(mean(le),1),
'\n Standard Deviation = ', round(sd(le),2),
'\n Sample Size = ', length(le),
'\n\nThe 5-number summary for Life Expectancy')
summary(le)
The standard descriptives for Life Expectancy
Mean = 71.6
Standard Deviation = 8.12
Sample Size = 183
The 5-number summary for Life Expectancy
Min. 1st Qu. Median Mean 3rd Qu. Max.
51.00 65.75 73.90 71.62 76.95 88.00
Applying **Robb’s Rule of Thumb,” notice that the mean and median are significantly differ (e.g. differ by more than \(\frac{s}{10}\) ) since
The absolute value of the difference is greater than a tenth of the standard deviation: $\(\frac{s}{10} = \frac{8.12}{10} = 0.812\)$
Robb’s Rule of Thumb says that, in this instance, we would expect skew and outlier. This confirms the work above showing a skew to the left and several outliers to the left.