Sampling Distributions and the Central Limit Theorem#
A key connection between probability and statistics is the concept of sampling distributions.
Sampling Distributions#
Definition. For a fixed population and fixed sample size \(k\in \mathbb{N}\), a collection of values of the mean over \(n\) samples of size \(k\) forms what we call a sampling distribution.
Suppose that we have a sampling distribution:
where \(\bar x_i\) is the mean of the sample \(X_i\).
For a sampling distribution, we know that:
The sample size is \(k\) for all \(X_i\).
The number of samples in our sampling distribution is \(n\).
We refer to the grand mean \(\bar x\) as the mean of the \(n\) sample means, e.g.
Two Vital Theorems#
The Centrol Limit Theorem (CLT) and Law of Large Numbers govern how sampling distributions work:
Central Limit Theorem. The means \(\bar x_i\) of a sampling distribution are approximately normal (bell-shaped) and centered upon \(\mu_0\), the population average. Additionally, as sample size \(k\) increases, \(\bar x \rightarrow \mu_0\).
Law of Large Numbers. As the number of samples \(n\) in our sampling distribution increases, our estimates of the population mean \(\mu_0\) increase in accuracy.
Thus, the CLT guarantees a bell-shaped distribution centered upon the population average, and the Law of Large Numbers works like a lever that allows us to control the accuracy. Increased sample size \(k\) leads to increased accuracy by the CLT, and increased number of samples \(n\) leads to increased accuracy by the Law of Large Numbers.
The Law of Large Numbers is vital due to the fact that the sample size is often limited. For example, sample size should be kept to less than \(10\%\) of the population size. The population of all SAT scores for Forsyth County, GA, in 2025 may contain a few thousand items, while the population of SAT scores for the United States will contain millions of items. When the size of the population the sampling distribution is drawn from is limited, the Law of Large Numbers allows us to take many more samples to improve accuracy.
Law of Large Numbers#
If \(\bar x\) is the grand mean of \(n\) many sample averages \(\bar x_i\) which are all have the same sample size \(k\) and are drawn from the same population (or distribution) with mean \(\mu\), then
Central Limit Theorem#
Assume \(\bar x\) is the grand mean of \(n\) many sample averages \(\bar x_i\) which all have the sample size \(k\) and are drawn from the same population (or distribution) with mean \(\mu\) and population standard deviation \(\sigma\). For large values of \(k\), this sampling distribution can be assumed approximately normal. Specifically, the sampling distribution can be assumed to be
Getting Started#
To prepare for the examples and demonstrations, we two things. First, we need data to work with. Second, we need our main sampling function: sample.data.frame.
Run the cell below to load 4 data sets.
Show code cell source
united <- read.csv('http://faculty.ung.edu/rsinn/data/united.csv')
pers <- read.csv('http://faculty.ung.edu/rsinn/data/personality.csv')
airports <- read.csv('http://faculty.ung.edu/rsinn/data/airports.csv')
births <- read.csv('http://faculty.ung.edu/rsinn/data/baby.csv')
We will use three functions to perform the sampling:
rflip – simulates a coin flip or binomial distribution.
rspin – simulates a spinner which allows for a couple different distributions.
sample.data.frame – draw a random sample of rows from a given data frame.
The code for these functions has been adapted from the documentation of the classic mosaic package which is still available in R given that you have the correct versioning for R and all mosaic’s required dependencies.
Run the cell below to activate the rflip() function:
Show code cell source
rflip <- function(n=1, prob=.5, quiet=FALSE, verbose = !quiet, summarize = FALSE,
summarise = summarize) {
if ( ( prob > 1 && is.integer(prob) ) ) {
# swap n and prob
temp <- prob
prob <- n
n <- temp
}
if (summarise) {
heads <- rbinom(1, n, prob)
return(data.frame(n = n, heads = heads, tails = n - heads, prob = prob))
} else {
r <- rbinom(n,1,prob)
result <- c('T','H')[ 1 + r ]
heads <- sum(r)
attr(heads,"n") <- n
attr(heads,"prob") <- prob
attr(heads,"sequence") <- result
attr(heads,"verbose") <- verbose
class(heads) <- 'cointoss'
return(heads)
}
}
Let’s run an example.
rflip(20, prob = 1/4)
Show code cell output
[1] 7
attr(,"n")
[1] 20
attr(,"prob")
[1] 0.25
attr(,"sequence")
[1] "T" "T" "T" "H" "T" "H" "H" "H" "T" "H" "H" "T" "H" "T" "T" "T" "T" "T" "T"
[20] "T"
attr(,"verbose")
[1] TRUE
attr(,"class")
[1] "cointoss"
Hint
Notice how the summarize = TRUE option organizes the output.
rflip(20, prob = 1/4, summarize = TRUE)
| n | heads | tails | prob |
|---|---|---|---|
| 20 | 3 | 17 | 0.25 |
Tip
To extract the successes, (e.g. “heads”), we use our knowlege of how data frames work. Below, we use [row,column] notation to grab the value showing the number of successes.
rflip(20, prob = 1/4, summarize = TRUE)[1,2]
For Loops#
We will use a for loop to create sampling distributions, and the instructions for how to set up and how to use for loops is linked. The code block we use for creating a sampling distribution with histogram is developed at the linked page.
Example 1: M&M’s#
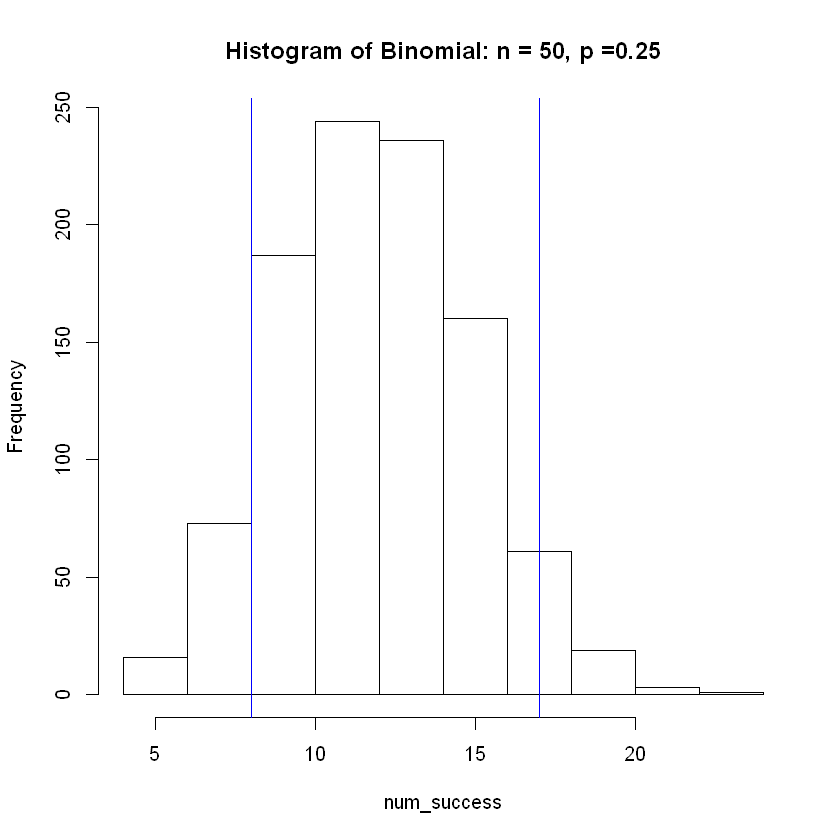
A collection vat in the manufacturing process at the M&M plant has millions of unsorted candies. There is 25% chance of drawing a red candy. What is the expected number of red candies that will be drawn if we draw a sample of size 50?
The main for loop is created below along with a display of middle 90% of the results distribution indicated by blue vertical lines.
num_success <- c() # create a vector to store the number of successes for each sample drawn
num_samps = 1000 # set the number of samples to be drawn
for (i in 1:num_samps){
temp <- rflip(50, prob = 1/4, summarize = TRUE)[1,2] # draw 50 candies, count numer of red
num_success[i] <- temp # count and store the number of red candies from this trial
}
lower <- quantile(num_success, prob = 0.05) # Calcuate the 5th percentile.
upper <- quantile(num_success, prob = 0.95) # Calcuate the 95th percentile.
cat('The mean of the simulated distribution is\n ',mean(num_success) )
hist(num_success, breaks = 8, main = 'Histogram of Binomial: n = 50, p =0.25')
abline( v = lower, col="blue") # Add vertical line at 5th percentile
abline(v = upper, col="blue") # Add vertical line at 95th percentile
The mean of the simulated distribution is
12.435
Expected Value#
The expected value for the binomial distribution is given by:
where n is the number of trials conducted and p is the probability of success. This table summarizes the investigation to include the example above along with the three below:
| n | p | np | Simulation Average | Middle 90% Interval |
|---|---|---|---|---|
| 50 | 0.25 | 12.5 | 12.403 | (7,18) |
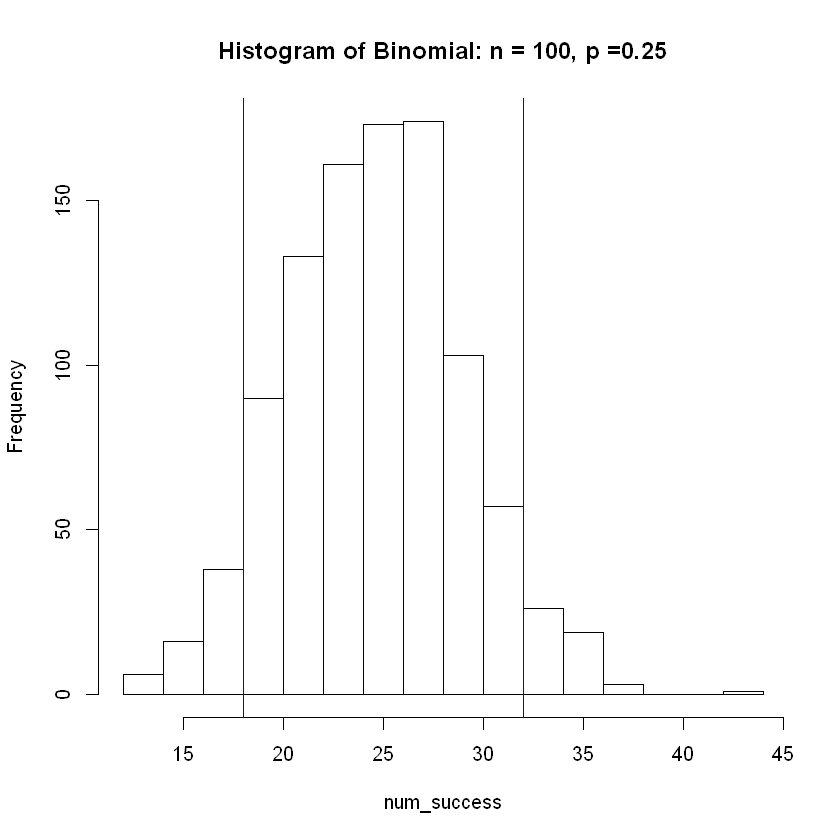
| 100 | 0.25 | 25 | 25.087 | (17,32) |
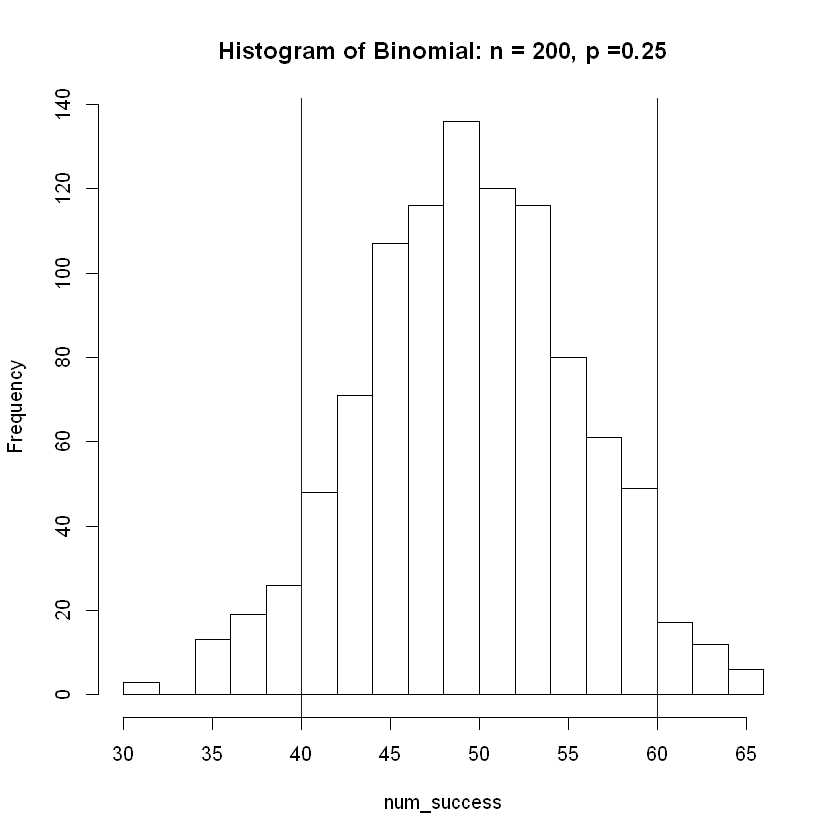
| 200 | 0.25 | 50 | 49.962 | (40,60) |
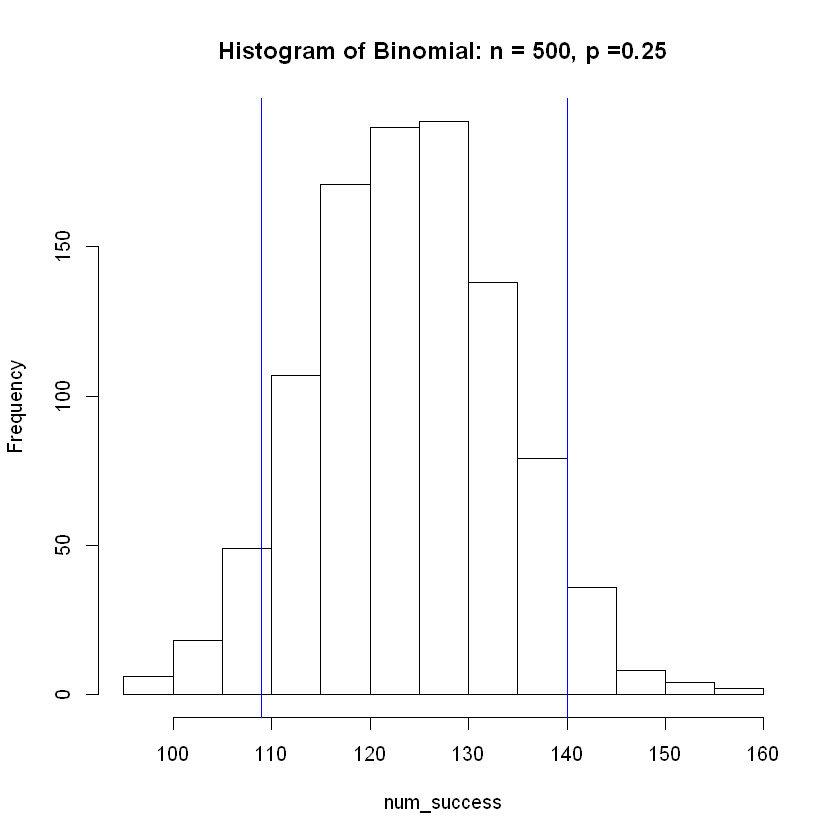
| 500 | 0.25 | 125 | 124.731 | (109,140) |
Note how the estimated average from the simulation becomes more accurate as sample size \(n\) increases. Also, the width of the interval as a percentage of the sample size grows smaller and more accurate as \(n\) increase.
These increases in accuracy as \(n\) increases shows the Central Limit Theorem at work.
num_success <- c() # create a vector to store the number of successes for each sample drawn
num_samps = 1000 # set the number of samples to be drawn
for (i in 1:num_samps){
temp <- rflip(100, prob = 1/4, summarize = TRUE)[1,2] # draw 100 candies, count numer of red
num_success[i] <- temp # count and store the number of red candies from this trial
}
lower <- quantile(num_success, prob = 0.05) # Calcuate the 5th percentile.
upper <- quantile(num_success, prob = 0.95) # Calcuate the 95th percentile.
cat('The mean of the simulated distribution is\n ',mean(num_success) )
hist(num_success, breaks = 15, main = 'Histogram of Binomial: n = 100, p =0.25')
abline( v = lower, col="blue") # Add vertical line at 5th percentile
abline(v = upper, col="blue") # Add vertical line at 95th percentile
The mean of the simulated distribution is
25.111
num_success <- c() # create a vector to store the number of successes for each sample drawn
num_samps = 1000 # set the number of samples to be drawn
for (i in 1:num_samps){
temp <- rflip(200, prob = 1/4, summarize = TRUE)[1,2] # draw 200 candies, count numer of red
num_success[i] <- temp # count and store the number of red candies from this trial
}
lower <- quantile(num_success, prob = 0.05) # Calcuate the 5th percentile.
upper <- quantile(num_success, prob = 0.95) # Calcuate the 95th percentile.
cat('The mean of the simulated distribution is\n ',mean(num_success) )
hist(num_success, breaks = 15, main = 'Histogram of Binomial: n = 200, p =0.25')
abline( v = lower, col="blue") # Add vertical line at 5th percentile
abline(v = upper, col="blue") # Add vertical line at 95th percentile
The mean of the simulated distribution is
49.95
num_success <- c() # create a vector to store the number of successes for each sample drawn
num_samps = 1000 # set the number of samples to be drawn
for (i in 1:num_samps){
temp <- rflip(500, prob = 1/4, summarize = TRUE)[1,2] # draw 500 candies, count numer of red
num_success[i] <- temp # count and store the number of red candies from this trial
}
lower <- quantile(num_success, prob = 0.05) # Calcuate the 5th percentile.
upper <- quantile(num_success, prob = 0.95) # Calcuate the 95th percentile.
cat('The mean of the simulated distribution is\n ',mean(num_success) )
hist(num_success, breaks = 20, main = 'Histogram of Binomial: n = 500, p =0.25')
abline( v = lower, col="blue") # Add vertical line at 5th percentile
abline(v = upper, col="blue") # Add vertical line at 95th percentile
The mean of the simulated distribution is
124.508
Example: Estimating Narcissism#
Let’s work with an example from the personality data set: narcissism. Let’s generate many, many samples of the same size. We’ll find the averages from each sample and use them to estimate the average level of narcissism for students at UNG.
First Step: Generating Samples of Size \(n=10\)#
Let’s begin with the R commands necessary to sample the Narc column in the personality data frame. We will use the
function to draw a sample. We first need to load the function.
Show code cell source
sample.data.frame <- function(x, size, replace = FALSE, prob = NULL, groups=NULL,
orig.ids = TRUE, fixed = names(x), shuffled = c(),
invisibly.return = NULL, ...) {
if( missing(size) ) size = nrow(x)
if( is.null(invisibly.return) ) invisibly.return = size>50
shuffled <- intersect(shuffled, names(x))
fixed <- setdiff(intersect(fixed, names(x)), shuffled)
n <- nrow(x)
ids <- 1:n
groups <- eval( substitute(groups), x )
newids <- sample(n, size, replace=replace, prob=prob, ...)
origids <- ids[newids]
result <- x[newids, , drop=FALSE]
idsString <- as.character(origids)
for (column in shuffled) {
cids <- sample(newids, groups=groups[newids])
result[,column] <- x[cids,column]
idsString <- paste(idsString, ".", cids, sep="")
}
result <- result[ , union(fixed,shuffled), drop=FALSE]
if (orig.ids) result$orig.id <- idsString
if (invisibly.return) { return(invisible(result)) } else {return(result)}
}
Run the cell below to see how this works, and notice:
The function inputs:
Name of the data frame to sample from.
Sample size to be drawn.
The output: 10 rows from the data frame with all columns present.
s <- sample.data.frame(p, 10, orig.ids = FALSE)
head(s,15)
Error in as.vector(y): object 'p' not found
Traceback:
1. sample.data.frame(p, 10, orig.ids = FALSE)
2. intersect(shuffled, names(x)) # at line 6 of file <text>
3. as.vector(y)
We can find the average narcissism for these 10 persons by subsetting our sample data frame s.
mean(s[ , 'Narc'])
Error in mean(s[, "Narc"]): object 's' not found
Traceback:
1. mean(s[, "Narc"])
Putting it Together. Eventually, we want to run a loop that does this a thousand or more times. Thus, we prefer a single line of code that will do it for us all at once. We wrap the sample.data.frame() function inside the mean function as shown below.
Run the code below multiple times to see how we’re sampling plus finding the average Narcissism level for each.
mean(sample.data.frame(p, 10, orig.ids = F)[ , 'Narc'])
Error in as.vector(y): object 'p' not found
Traceback:
1. mean(sample.data.frame(p, 10, orig.ids = F)[, "Narc"])
2. sample.data.frame(p, 10, orig.ids = F)
3. intersect(shuffled, names(x)) # at line 6 of file <text>
4. as.vector(y)
Step 2: Creating a for Loop#
The steps make sense if we consider them separately:
Create all_means, an initially empty vector where we plan to store our sample means.
Create a for loop that will a thousand times.
Inside the loop, we will:
Gather a sample of size \(n=10\).
Calcuate the mean.
Add this value to the all_means vector.
all_means <- c() #Empty vector to store all the sample means
for (count in 1:1000){
sample <- sample.data.frame(p, 10, orig.ids = F) #Generate a sample (size n=10)
all_means[count] <- mean(sample[ , 'Narc']) #Save the mean of this sample in my list
}
Error in sample.data.frame(p, 10, orig.ids = F): object 'p' not found
Traceback:
1. sample.data.frame(p, 10, orig.ids = F)
2. intersect(shuffled, names(x)) # at line 6 of file <text>
3. as.vector(y)
Notice that we now have a vector all_means, so we display the distribution in a histogram and caculate various statistics.
summary(all_means)
hist(all_means, main = 'Histogram: Narcissism', xlab = 'Narc')
Length Class Mode
0 NULL NULL
Error in hist.default(all_means, main = "Histogram: Narcissism", xlab = "Narc"): 'x' must be numeric
Traceback:
1. hist(all_means, main = "Histogram: Narcissism", xlab = "Narc")
2. hist.default(all_means, main = "Histogram: Narcissism", xlab = "Narc")
3. stop("'x' must be numeric")
Step 3: The Middle 90% of the Distribution#
Because we intend to use the sampling distributions to estimate the population average, we need a way to gather an interval. This interval will be our estimated range of values. For the moment, let’s use the middle 90% of the all_means vector. We will need the endpoints, e.g. the 5th and 95th percentiles from the vector.
lower <- quantile(all_means, prob = 0.05) # Calcuate the 5th percentile.
upper <- quantile(all_means, prob = 0.95) # Calcuate the 95th percentile.
cat('The middle 90% of the all_means vector is (',lower,',',upper,').')
The middle 90% of the all_means vector is ( NA , NA ).
Step 4: The Histogram with Vertical Lines Showing the 5th and 95th Percentiles#
We use the function abline() to superimpose vertical lines onto our histogram. We’ve already calculated the values for the 5th and 95th percentiles. We need only to use the option v which draws a vertical line at the value indicated. The color option is not vital for our purposes, but a splash of color is visually appealing.
As we go forward, we will see that increased sample size will lead to a narrower bell-shape. In other words, the size of the standard deviation will become important, so let’s include that in the text we print out using the cat() function.
cat("Standard deviation of sampling distribution:", sd(all_means), '\nThe middle 90% of the sampling distribution: is (',lower,',',upper,').')
hist(all_means, main = 'Histogram: Narcissism', xlab = 'Narc')
abline( v = lower, col="blue")
abline(v = upper, col="blue")
Standard deviation of sampling distribution: NA
The middle 90% of the sampling distribution: is ( NA , NA ).
Error in hist.default(all_means, main = "Histogram: Narcissism", xlab = "Narc"): 'x' must be numeric
Traceback:
1. hist(all_means, main = "Histogram: Narcissism", xlab = "Narc")
2. hist.default(all_means, main = "Histogram: Narcissism", xlab = "Narc")
3. stop("'x' must be numeric")
Step 5: Performing all Tasks in 1 Code Block#
Now that we have unpacked each command line needed, we can put it all together into one code block. We have also added the parameters reps and samp_size as the top 2 lines to make it easy to set them to a single value. Doing these tasks will help to quickly generate different sampling distributions for different sample sizes n.
reps = 1000 # Number of repetitions of FOR loop
samp_size = 10 # Sample size to be drawn
all_means <- c() # Empty vector to store all the sample means
for (count in 1:reps){
sample <- sample.data.frame(p, 10, orig.ids = F)
all_means[count] <- mean(sample[ , 'Narc'])
}
upper <- quantile(all_means, prob = 0.95)
lower <- quantile(all_means, prob = 0.05)
cat("Standard deviation of sampling distribution:", sd(all_means), '\nThe middle 90% of sampling distribution: (',lower,',',upper,').')
hist(all_means, main = 'Histogram: Narcissism', xlab = 'Narc')
abline( v = lower, col="blue")
abline(v = upper, col="blue")
Error in sample.data.frame(p, 10, orig.ids = F): object 'p' not found
Traceback:
1. sample.data.frame(p, 10, orig.ids = F)
2. intersect(shuffled, names(x)) # at line 6 of file <text>
3. as.vector(y)